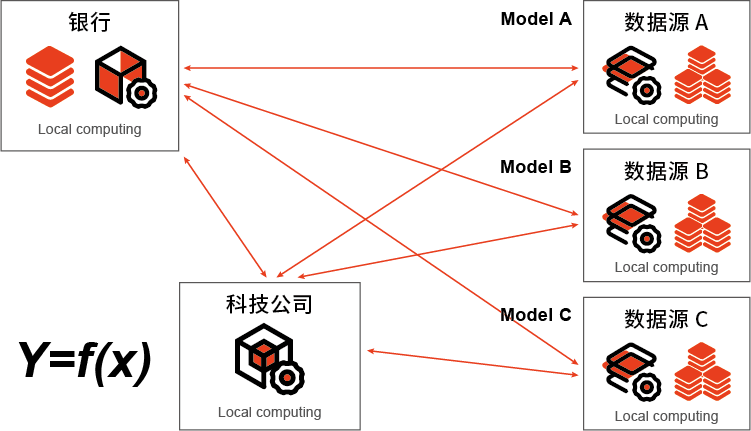
产品介绍
MaximAI是天云数据的通用PaaS化AI建模平台产品。旨在突破Hadoop/Spark的使用瓶颈,致力于降低AI落地成本。实现AI模型标准化、流程化、批量化生产,让每家企业都具有开箱即用的AI能力。已成功应用于银行、保险、医药、石油等多个行业。
功能要点
- 主流的机器学习算法免代码模式建模,包括但不限于随机森林、梯度提升模型、深度学习、广义线性模型、XGBoost、K-means等算法;菜单式算法参数调整,包含算法参数讲解描述,便于业务人员对参数的调整;
- 自动化机器学习,包括自动化模型选择和参数选择,以及自动模型集成,支持模型以指定评估指标的排列展示;
- 集成Python等编程语言的开发环境,支持目前主流的开放式学习框架,包括但不限于Spark MLlib、TensorFlow等开源框架;
- 企业级的管理功能,包括但不限于用户管理、数据管理、模型管理、系统管理等。
产品价值
- 全量数据无偏建模:全量数据无偏建模,为企业提供简单易用的建模界面和模板;
- 加速知识应用:通过拖拉拽的方式即可完成模型建模,避免不同团队之间的知识壁垒与矛盾,加速知识应用;
- 满足业务爆发需求:从企业的生产制造、供应链、营销与销售、交付与服务等价值链,每个环节都存在可利用AI改善的空间,为企业业务条线降本增效;
- 降低建模人员门槛:使不熟悉编程的数学/统计背景人员具备建模能力,普通业务人员也可操作建模;
- 流程可回溯模型可复用:支持对数据的统计分析和可视化探查等功能,建模流程可回溯,模型可重复复用;
- AI产业化:MaximAI能够提升模型性能、可扩展性、可解释性和准确度,还能优化资源配置,提升模型开发效率和业务敏捷度相应,最大化AI价值。