
Hubble数据库x某医院 基因图谱构建节点总量9万、关系总量20万
众所周知,新药研发成本高、周期长、失败率高。根据德勤(Deloitte)报告,2017年全球TOP12制药巨头,成功上市一个新药的成本为20亿美元。CFDA批准临床实验的数量大幅下降,药物从研发到上市通常要8-12年时间,在研发上的投资回报率仅有3.2%,相比2010年的10.1%降幅显著。
靶点是新药研发的基础,一个靶点可以成就一个产业:我国目前绝大部分创新药物还是在发现的作用机制、作用靶点基础上研发出现的,因此药物创新的突破,还是要从靶点的发现做起。但其实靶点就如同金字塔的一块特定石头,就在那,可要准确找到,却不容易。药物开发的关键是如何在大量的潜在靶点中筛选出最有可能获得成功并应用于临床的靶点。
在靶向药物使用之前,做基因检测以明确具体有没有靶点:如果肿瘤病人的驱动基因发生了突变,针对驱动基因突变可以使用相应的靶向药物。在如肺癌、乳腺癌、结肠直肠癌等癌症中都能发现明确的致癌基因。如EDFR基因ALK基因突变都是肺癌,针对这两个基因有相应的靶点靶向药物,如吉非替尼,克唑替尼等。如有这两个基因使用靶向药物会比化疗或者放疗效果要好,因此在寻找药物与基因之间的关系也和药物与靶点的关系有一定的关联。
同源蛋白是指氨基酸序列具有明显的相似性,在不同生物体或同一机体内行使相同或相似功能的蛋白质,一般来说两条基因序列相似性达80%可以成为同源蛋白。
人工智能时代,新药的研发从实验检测转向数据分析,通过数据模拟加速检测药物晶型及对应的适应症或副作用。药物开发和研究失败的最大原因之一是因为药物靶向单个致病基因。利用人工智能一次绘制出数百种导致疾病的基因,然后开发出能够针对所有致病基因的药物,快速找到复杂疾病的解决方案。人工智能可以通过大量数据筛选并快速挑选合适的化合物,直接较少了研发时间,节约研发成本,降低研发风险,使新药研发更加有效率。
Hubble数据库基因图谱构建节点总量9万、关系总量20万:Hubble数据库在某医院项目主要通过药物与基因之间的作用关系,和基因与基因之间的关系寻找到解决方案:已知A药物作用于a基因,通过关系将a基因与b基因,c基因相连接,看是否可以将A药物作用于b基因或者c基因,来解决与b基因c基因有关且暂无药来治疗的疾病。
以基因PCDH19为例:CALCIUM药物对PCDH19基因有作用,以及两种与该基因相关的疾病:早期婴儿型癫痫性脑病、PCDH19-related癫痫综合征。
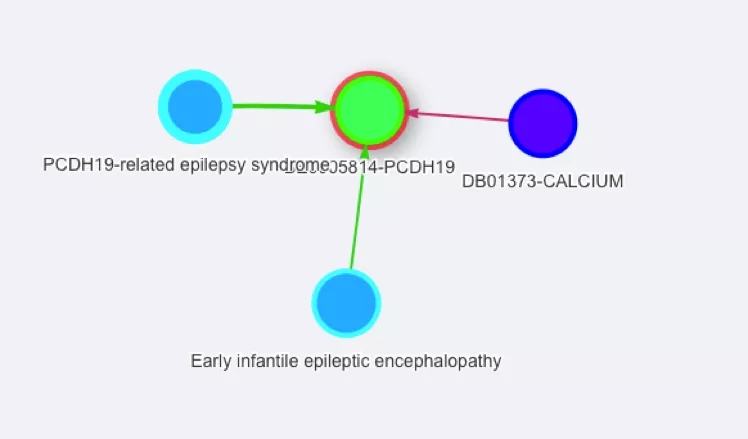 图1基因与疾病药物关系图
图1基因与疾病药物关系图
以某种特定的联系(项目以代谢通路,同源蛋白的方式)将基因分组分类,如寻找到与PCDH19基因序列相类似的基因有PCDH8,PCDH18等。
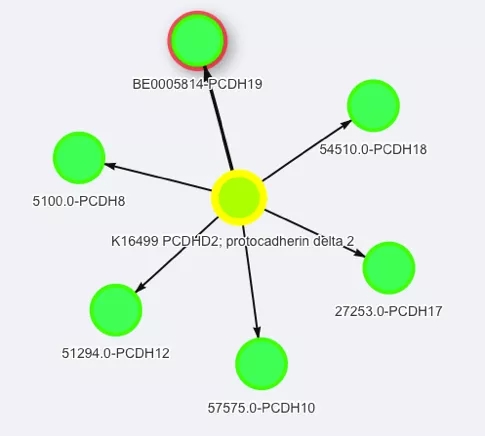 图2 同源蛋白基因
图2 同源蛋白基因
那么是否与Diencephalic-mesencephalic junction dysplasia syndrome(间脑-中脑交界处发育不良综合征)有关的基因PCDH12且暂无药物治疗,使用CALCIUM药物是否可以抑制该疾病。
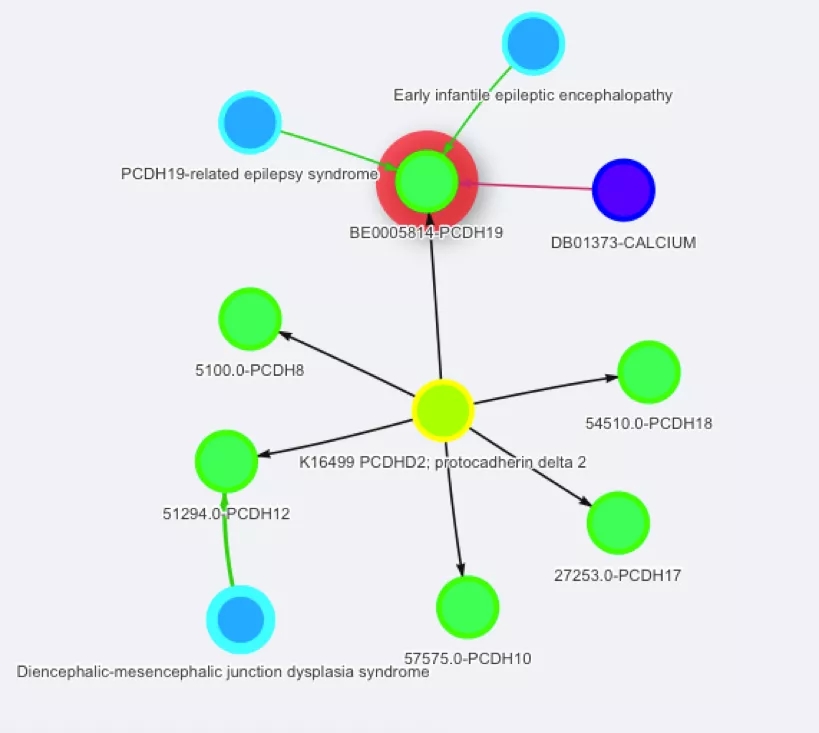 图3同源蛋白与基因与疾病关系
图3同源蛋白与基因与疾病关系
检验结果如下:
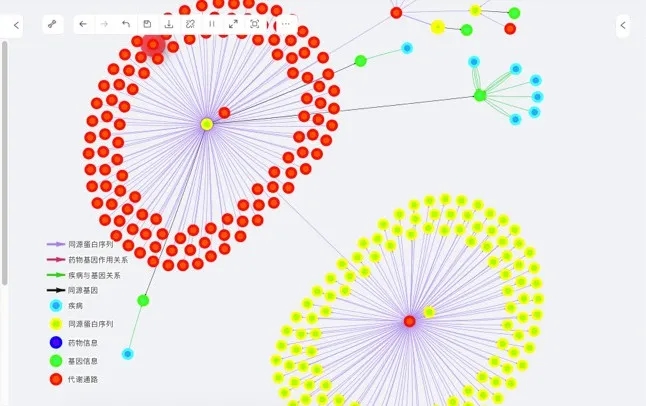
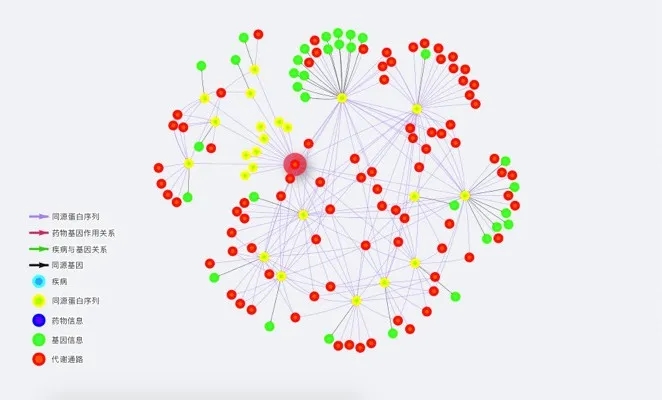
以该方案组合各个基因数据,将大量数据呈现出来,图谱构建节点总量9万、关系总量20万,以供专家通过此形式来寻找相应靶点尝试药物要解决一些暂时不可治疗的疾病。