

我们知道,原本每个C端受众都可以自己给ChatGPT喂文件,他的定位就是通用大模型。但从这次发布来看:
首先,ChatGPT从性质已经从通用大模型变成了专属大模型,与此同时服务降价了。私域模型复杂度远高于通用模型,以行业通情,私域模型定价也会高于通用模型。那为什么ChatGPT从通用模型步入到私域模型,反而价位降低了呢?因为它已经从从训练阶段走向服务阶段(Training to Serving)了。
以大模型的整个服务流程来看,大模型只占其中一个环节。而且大模型已经从Training to Serving了,成本走低可以主推服务了。
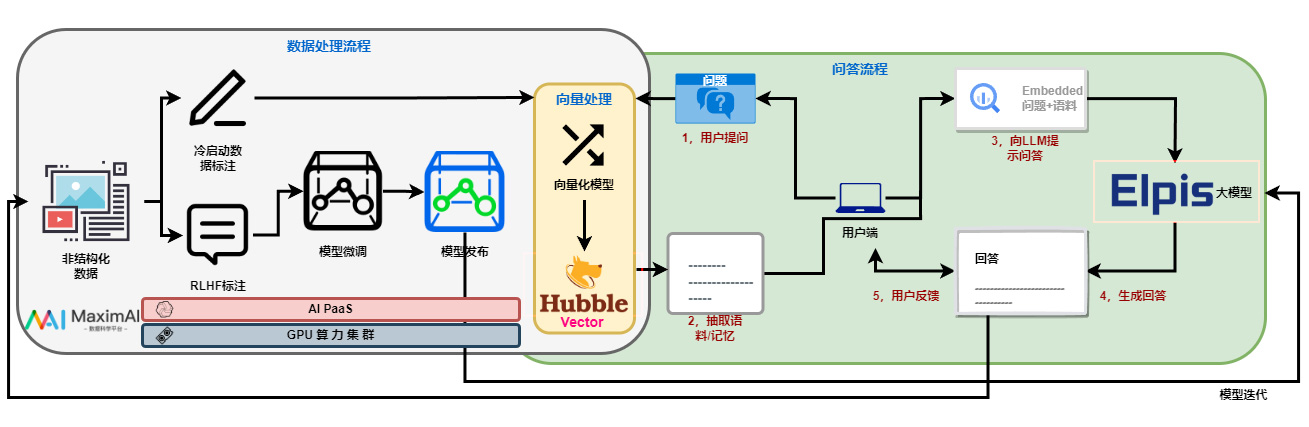
(天云数据大模型服务图)
对于开放新模态API,这其实就是工程就绪整理能力。目前Hugging face上37万+Transformer开源模型,各种多模态上的小模型都被打包在一个服务实体里头,可以用 API 方式调用,只要有平台和环境就可以就绪。
针对这次OpenAI新品“升级降价”,天云数据对比技术来看,可喜的是,国内科技厂商并没有离一线很远。
但是,我们也必须意识到差距在哪并客观的看待差距——OpenAI做的是在线就绪服务,而我们是做了一个工具。
OpenAI的服务可以直接线上SaaS 服务的形式,而产品属于工具,这就是落差。这落差核心体现在产业上,科技厂商得拿工具的能力去置换用户的想法,然后用户再买机器再投产服务,它至少是周级别的。要想聚合这三层能力,要么就是自己投资建设服务出来,要么就是国内厂商生态抱团,软件厂商和硬件厂商一起攒服务。目前市场对国内大模型普遍不看好,那是因为现在用户还看不懂,用户没有刚性需求、提不出来精准目标,就看不到更好的服务样板。大模型服务需要启动大的技术集群,这也是现在中国产线当中缺市场要素的转化。
因为流动的、高密度价值的数据信息都在企业的数据库里,因此要解决三个突出矛盾:
第一个矛盾,是动态模糊的意图和精准结构化查询语句SQL之间的这个矛盾;
第二个矛盾,是序列化的线性逻辑和错综复杂的数据关系之间的矛盾,需要用数据编织、存算分离等手段来完成对大模型的供给;
第三个矛盾,大模型使数据服务下沉到个体,带来大量远超于传统数仓数据可视化技术所能支撑的并发服务,对混合负载HTAP数据库形成刚性需求。
事实上,我们都知道,无论“轮子”多好,但只有“轮子”是肯定不行的,唯有学会如何造车才能发挥好轮子的价值。