
这是一个首创的集聚当今国内有影响力的通用大模型和资产管理垂直领域大模型开发应用的数智金融前沿技术发展大会,也是一个在上海国际金融中心城市集聚当今金融资管领域有影响力数智技术专家学者的大会,强烈吸引了业内外、海内外专业技术人士。全天大会历时9个多小时,线上参会约230万人次、现场参会近500人。
ITDC 2023现场检验大模型回答资管行业问题的能力
提问完,白院长也做了总结:定式回答是2家;但是比较新的回答是3家,还需要加上北交所;但是加上北交所就完事了吗?还有港交所、台交所,港台也是中国的一部分。
天云数据专注私域大模型,支撑证监会全部法规(不含更新数据),针对证券行业问题回答正确且有完整溯源。
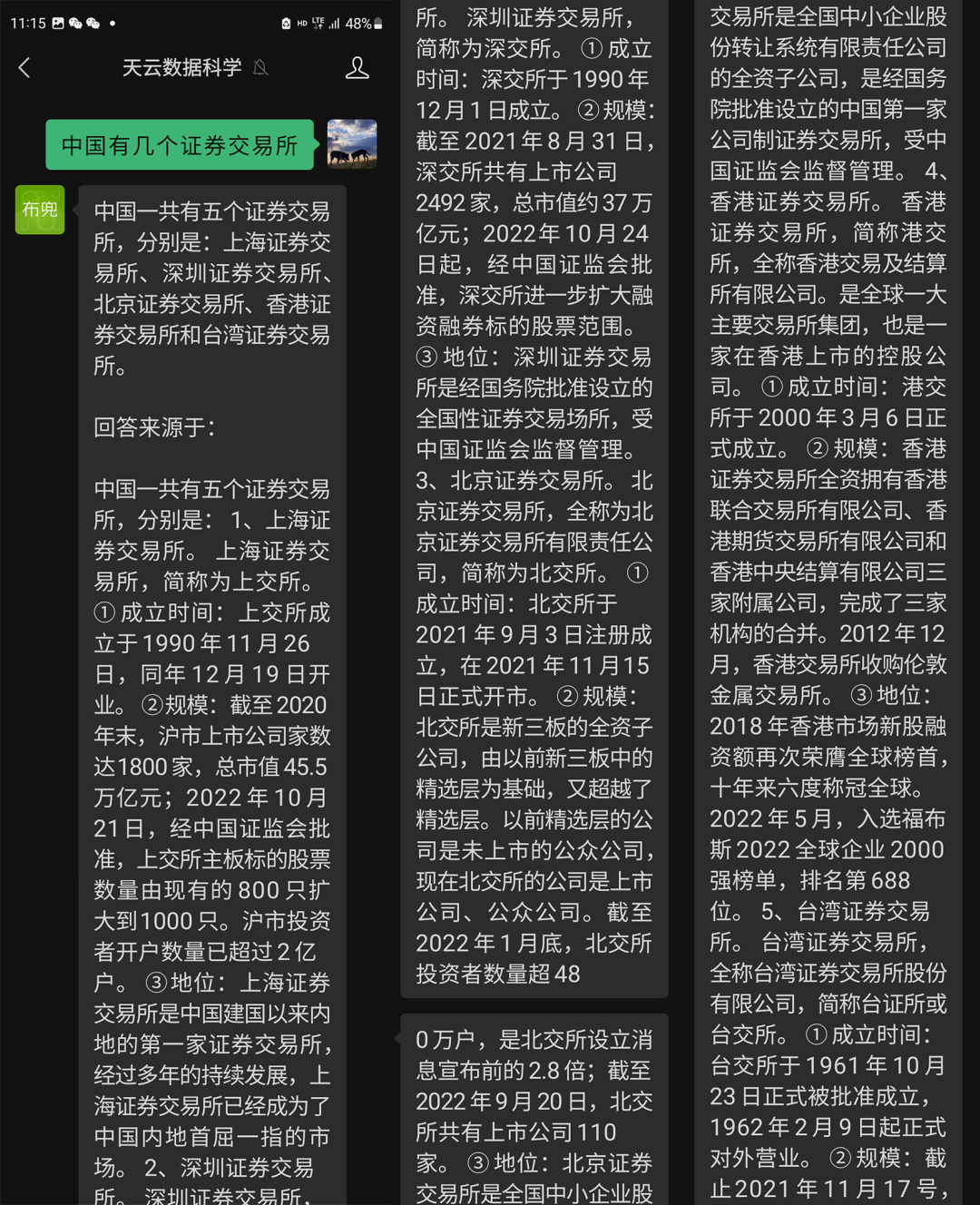
(天云数据的回答)
为什么天云数据大模型能精准回答且做到溯源?
Elpis已经从Training 步入Serving实现大模型2.0阶段
私域模型不是小模型,不是通用模型版的裁剪版,从通用模型到私域模型,是从“造轮子”到“造车”的过程。天云数据大模型已经实现从1.0的造轮子(Training)到2.0的Serving(造车)阶段,结合企业自己的私域数据、算力,保障行业数据的安全性,完成行业大模型实现大模型的新阶段。
天云数据私域大模型Elpis基于迁移学习对大语言模型进行微调,使模型语境更适用于当前私域数据场景,并且做到答案可精确溯源,最后通过模型管理进行服务的发布供用户使用。在生成时可以引用原有法条做准确严谨回答,对比通用大模型,更适合机构私有数据。
为什么大模型火爆之后资本将重点都转向了向量数据库?为什么云原生越来越重要?为什么OpenAI做大模型要外采Ray和Wandb,自动化机器学习对大模型有什么价值?通过一体机训练的逻辑能不能走向大模型的未来?针对这一系列问题,天云数据CEO雷涛会上分享的《去除幻像的大模型落地路径》给了我们答案。

那么到底是做向量数据库还是在现有数据库中加上向量引擎?北美的向量数据库创业公司Chroma,底层使用是实时分析数据库ClickHouse。“仅仅”是在著名实时分析数据库ClickHouse上封装了一层而已,Chroma便一跃成为新晋向量数据库,由此可见一斑。与其投资新的向量数据库项目,还不如关注现有数据库中哪些加上向量引擎可以变得更加强大。
这也是Databricks用AI释放数据潜力的方法。因为Databricks历来都有自研的AI产品,具备技术能力发布大模型产品释放数据价值。
天云数据在行业率先发布了私域数据大模型Elpis,其背后的技术支持框架是天云数据AI-PaaS平台除了自身的机器学习平台套件外,还兼容集成开源机器学习框架,Pytorch/TensorFlow/ Ray/Wandb/MXnet/Padddle等, 可以快速训练及发布推理服务。强化学习完成大模型的有监督学习,实现大模型正确理解人类意图。

能提供Agent服务一定会有一个前提,就是产业有完善的AI Infra。近期人工智能的热点主要体现在生成式模型上,但无论是将私域数据迁移,还是需要一些向量化的数据库支撑还是Generative Agents以及强化学习RLHF都需要借助传统机器学习的方法和流水线来完成。甚至在BERT小模型阶段还依赖于知识图谱KG的严谨推理方式的工程组合,这些都需要科创公司就绪全栈AI的能力。
面向大模型的训练和开发部署,一定是更强的Base Model和比SFT指令数据更进一步反馈的数据是突破瓶颈的方向。开源社区模型不具备真正智能,更好的小模型来自大模型的Scale Down。
在中国的市场,一个新事物落地要想完成最小级闭环很难通过生态的之间的合作来完成,因此需要一个全栈技术的持续投入,尤其是LLM之上的AI Infra,没有所谓秘方和捷径。