
2018年6月13日,天云大数据产品发布暨渠道招募会在京举行。本次论坛以“AI浪潮下,如何参与DT转型”为主题,来自投资、国际第三方独立咨询公司、媒体等十余位业内重量级嘉宾进行了精彩分享,数百名科技、金融、能源等领域从业者、投资人参会。
天云大数据
数据科学家冯晟博士的演讲实录

今天的主角是天云MaximAI3.0产品。实际上之前的1.0、2.0,其实是解决了自动化的问题和批量化建模的问题,3.0我们突出的是智能化建模。实际上这三代产品都是现实的驱动,而不是凭空构建的产品。“不忘初心,方得始终”,我想我们还是有必要回顾一下AI到底是什么。


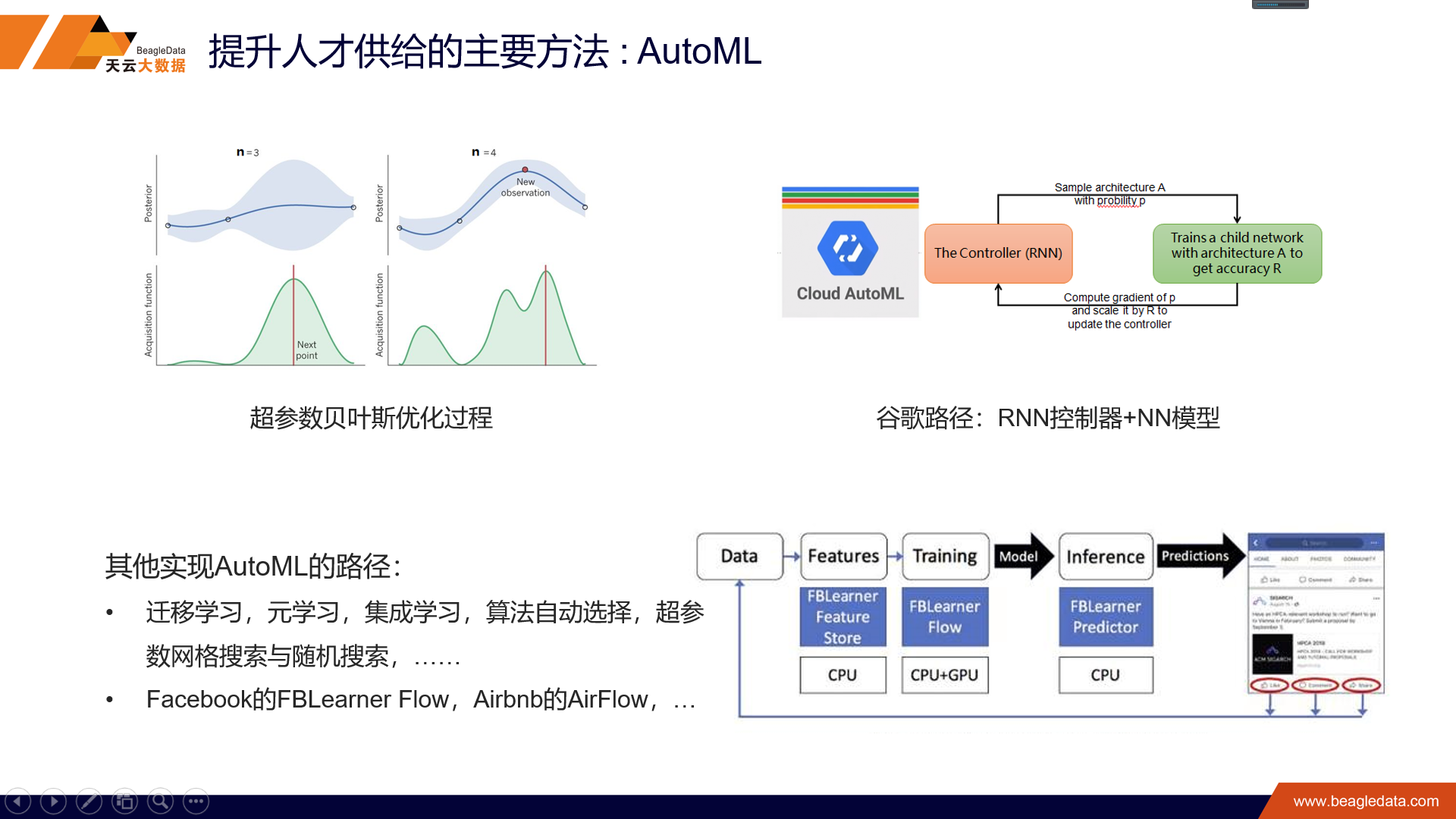
我们在MaximAI3.0支持了一些新型算法,像GMM还有XGBoost,还有遗传算法。这里面我稍微举两个例子。就是说大家可能有这样的经验,坐飞机的时候经常需要坐摆渡车,而不是直接从廊桥登机,这个遗传算法就是可以最大化的提升从廊桥登机的比例,最后我们实现的是飞机的停桥率能够超过90%。XGBoost的算法是比较新的,2016年出来的算法,这个算法的好处是加了正则项,还有做了一些二阶的处理,效果更好一些。这个模型我们用于场外配资识别。大家可能知道2015年的股灾,提到这个股灾可能大家脑子里想到的就是杠杆,而杠杆很重要的一个实现的工具就是这个场外配资。但这里面我们通过对账户的资产情况还有它的交易情况,还有它持仓情况,我们总结了一系列的特征,最后通过XGBoost可以实现这种场外配资账户的识别,最后召回率达到80%的时候,我们的模型准确率可以达到95%。
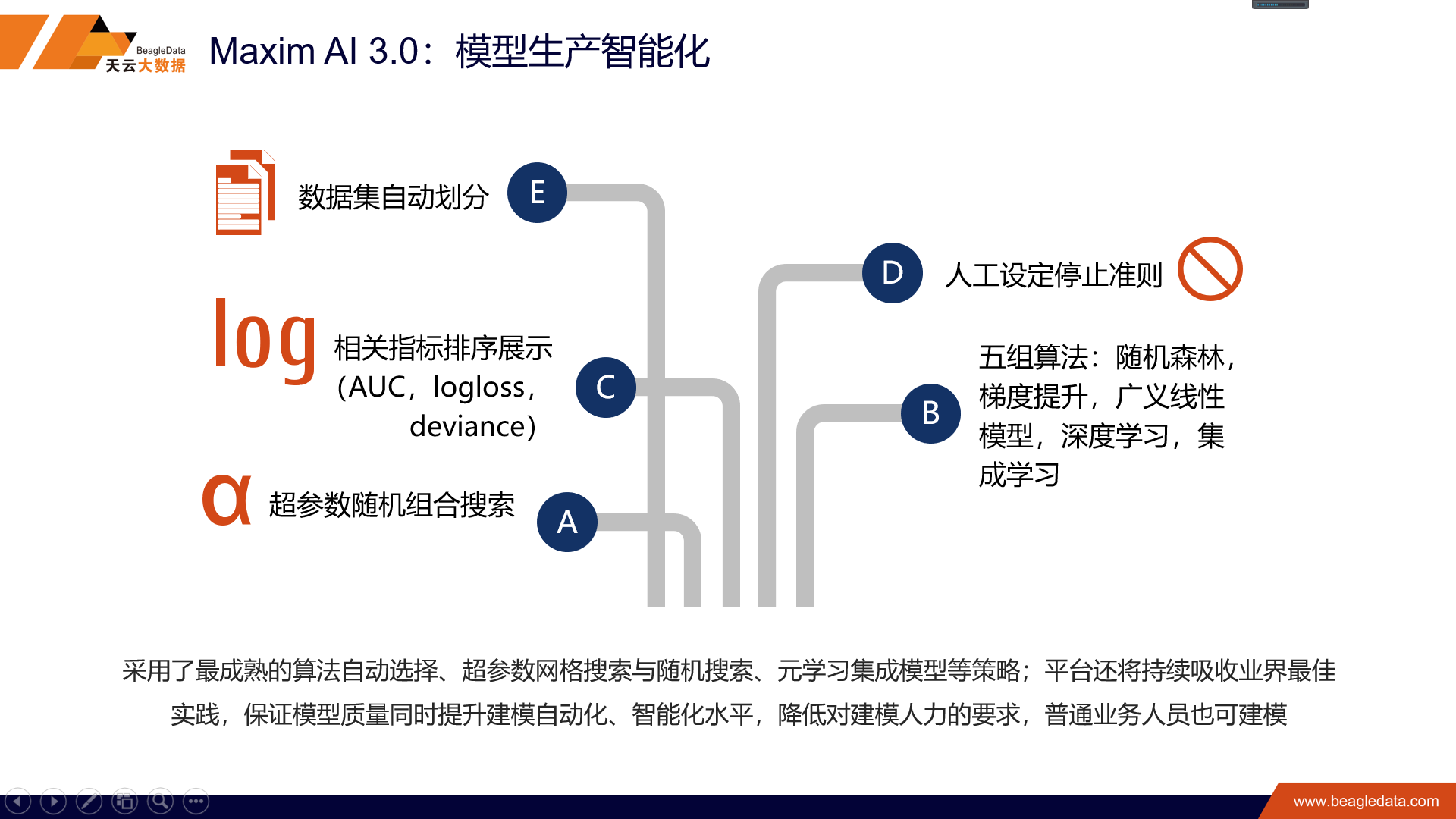
借由MaximAI3.0这些特性,我们最希望实现的就是通过这种分布式的强大的算力,我们去取代数据科学家调参的过程,相当于把科学家的经验用机器去解决,这样大大降低了我们建模的门槛。只有少量经验的业务人员也可以去建模。
这个是3.0平台出来的一个拖拉拽的建模截屏,大家可以看到它不仅是免代码的建模方式,而且是一个完全鼠标拖拉拽,降低了建模的难度。刚才讲了那么多机器自动学习的事,是为了自动化建模。模型建好了以后还有一个问题,就是如何上线生产的问题。机器学习占了AI很少的一块,机器学习之前比如像环境的配置,数据的治理,还有我们特征工程,还有资源管理,还有底层的服务,包括后面模型的上线,这些都是AI我们要处理了一些问题。所以说AI离我们最后的普及大众很大的一个困难就是我们如何去处理这些,这些实际上在我们的2.0时候,基本上都已经解决了,现在2.0里面都是包括的,我们提供的是一个端到端的建模过程,我们在3.0里面更多提到的是如何解决模型上线部署的问题。一个著名的出版商O’Reilly的VP曾经说过,一个模型生产只用了三个月,但是模型十个月过去了都没有上线。最后一公里是制约我们最后AI能够从生产到落地的很大的障碍。另外就是涉及到安全的问题,tensorflow是谷歌的开源的深度学习的框架,我们的tensorflow建立的模型如果要上线的话,谷歌是支持一套叫tensorflow serving的这么一套框架去上线的,但是这个服务是在谷歌那边,我们需要把数据发给谷歌,谷歌再返回来,这种安全性是不言而喻的。
我们3.0容器化部署同时解决了这两方面的问题,简单说就是我们将3.0生成的模型和模型所依赖的环境完全打包,形成这么一个容器化的Docker镜像,客户部署好Docker环境以后,直接可以把这个镜像在Docker上运行,这个极大的加快了模型上线生产的速度。整个的服务在客户这边本地化运行,安全性得到了保障。
希望在这种新的时代,我们的AI能够产生新的商业模式,产生新的合作方式,这里面我们所提倡的就是一种AI生态,这种生态有点类似于安卓。在安卓出来之前我们去开发一个手机应用,其实是非常耗时耗力的,安卓出来以后很多标准化的接口,可能几个人花一两周的时间就能开发一个小的应用,天云也是希望通过MaximAI3.0这个智能化建模的流水线平台,我们各行各业的数据进入到平台以后生成这些微服务,这些所谓的微服务就是一个个的模型,这些模型就类似于我们在安卓或者是iPhone AppStore里面的微服务商店。在未来的时候同一个行业里面有同样的建模需求的时候,我们这些微服务都可以复用到那些场景,从而实现普惠AI的作用。值得一提的是我们这些微服务一旦从MaximAI3.0生产出来以后,完全可以脱离MaximAI3.0运行,就是我刚才说的容器化部署的方式,大家不用担心必须得依赖MaximAI3.0,而是完全可以独立的。
这么多年天云在各行各业都积累了一些经验,比如说像交易数据我们银行方面风控方面的,像交易反欺诈,还有申请评分等等这些模型,在行为数据方面我们跟海关、人行、证监会做了一些监测违法行为的模型。还有就是在传感器的数据领域,我们跟能源行业做了一些模型。这是我们在银行做的一个申请反欺诈的,我们使用的是MaximAI平台,用的是深度学习算法,最后我们达到反欺诈的识别率能够高达92%。这个是我们在汤森路透做的一个案例,这个案例说的是每年都有大量的上市公司的公告,大概是几十万份,以前都是依靠人力的金融分析师去分类,分成分发、存储和转债等类别,现在通过NLP处理和后面的建模,可以直接通过机器以很高的精度把他们区分开,每年可以阅读上市公告高达二十万份以上,等于替代了十位的高级金融分析师。
还有一个案例是我们在辅助医疗的领域,这个领域是我们跟阜外医院合作的,它本身有一个模型,根据我们身体检测的指标去判断病人需不需要做CT,我们新的模型相比原来的模型有一定幅度的提高,这样的话这个提高可以带来一百五十亿医疗资源的节省,有一些病人可能并不需要做CT。希望在这样一个AI时代里,大家能够乘着AI的东风。天云愿意和大家一起并肩努力,最后希望能把大家的数据资产转化为现实的利润,谢谢大家!