
2018年6月13日,天云大数据产品发布暨渠道招募会在京举行。本次论坛以“AI浪潮下,如何参与DT转型”为主题,来自投资方、第三方独立国际咨询公司、媒体等十余位业内重量级嘉宾进行了精彩分享,数百名科技、金融、能源等领域从业者、投资人参会。
如下是天云大数据
研发总监乔旺龙的演讲实录

研发总监乔旺龙
首先来讲Hubble是什么?它是一个HTAP数据库。我今天将从发展、产品特性和案例三个维度来介绍。
Hadoop生态体系是一个复杂的场景,包括批处理,图计算等等一系列的场景,我们从2012年开始在大数据领域耕耘,在整体大数据生态体系中都有丰富的项目经验积累,如果说从传统的厂商要进入到大数据领域,需要经历一个很长一时间的磨练,从Hadoop生态系统中涉及到的各种技术和业务融合、各种组件框架之间的整合等等都要掌握,在此我们发现到在整体Hadoop大数据生态体系中尚没有OLTP的解决方案,更没有融合OLAP与OLTP场景的解决方案,从以上两点出发就是我们研发Hubble的初心。

我们回顾以往的技术体系,从传统世界进入到大数据体系,从我们最先了解的关系型数据库,比如Mysql、Oracle,还有扩展型数据库MPP,以及NoSQL数据库。它们之间虽然各有千秋,但是进入整个DT的数据时代,它们就差强人意了。今天我们讲Hubble怎么解决这样的问题,怎么使它更容易的进入到整个生态体系里面去。
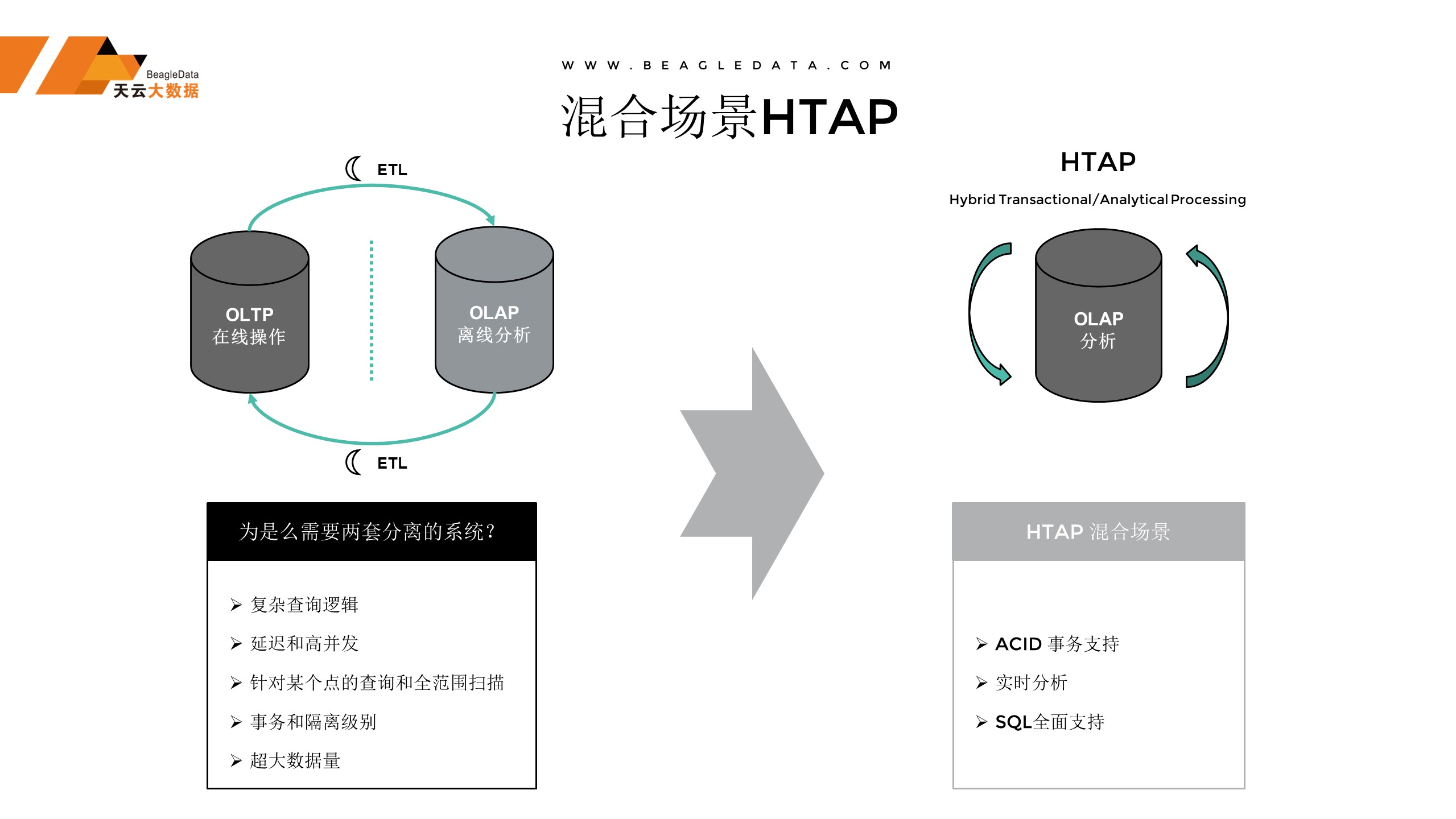
解决问题之前,我们先来普及一下,什么是HTAP库,在传统的业务场景里面分OLTP和OLAP,OLTP是什么?传统的OLTP是一种在线的服务,OLAP可以理解为数据仓库,每天晚上会从OLTP的数据不断地,搬到仓库里面去,仓库里面的数据加工分析完成后再搬回来,这是一个整体的传统架构下的场景。也是我们比较常用的场景,但是它依赖于两套分离的业务系统,为解决这个问题,我们研发了HTAP的库,它是OLTP加上OLAP在一起的库,数据都在一个平台,不再需要搬家,数据就在这儿,直接可以做各种业务处理。
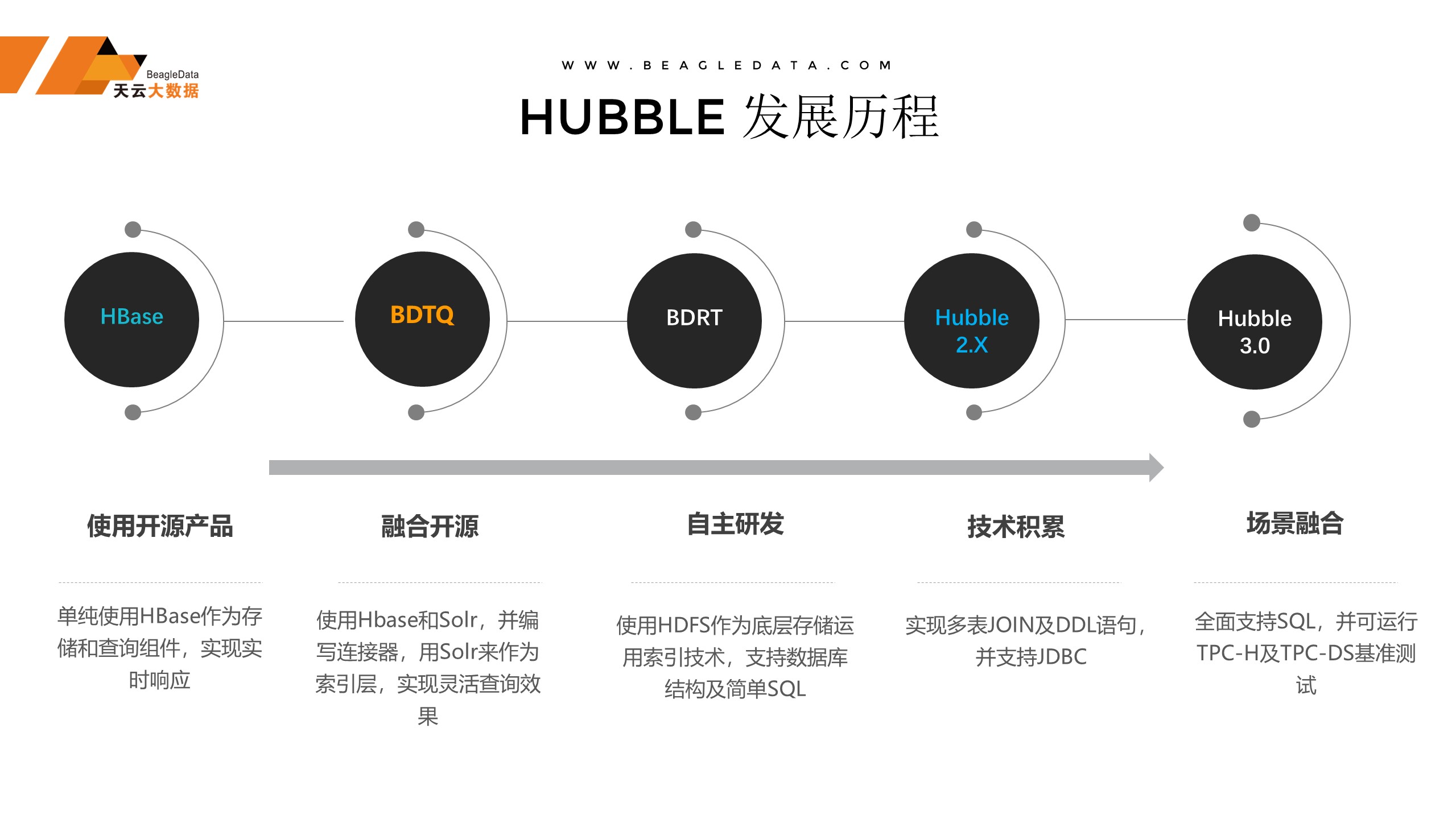
Hubble的发展历程是一个漫长的过程,不是一蹴而就的。天云从最开始做项目一直慢慢积累,从最开始使用开源,包括做开源融合,一直到最后做自主开发和场景融合,这是我们在不断地改进这种开源包括融合开源之后产生的一套体系。今天我们要讲的就是Hubble3.0,它是一个实现场景融合的工具,场景融合实现的OLTP与OLAP场景融合的一款产品。
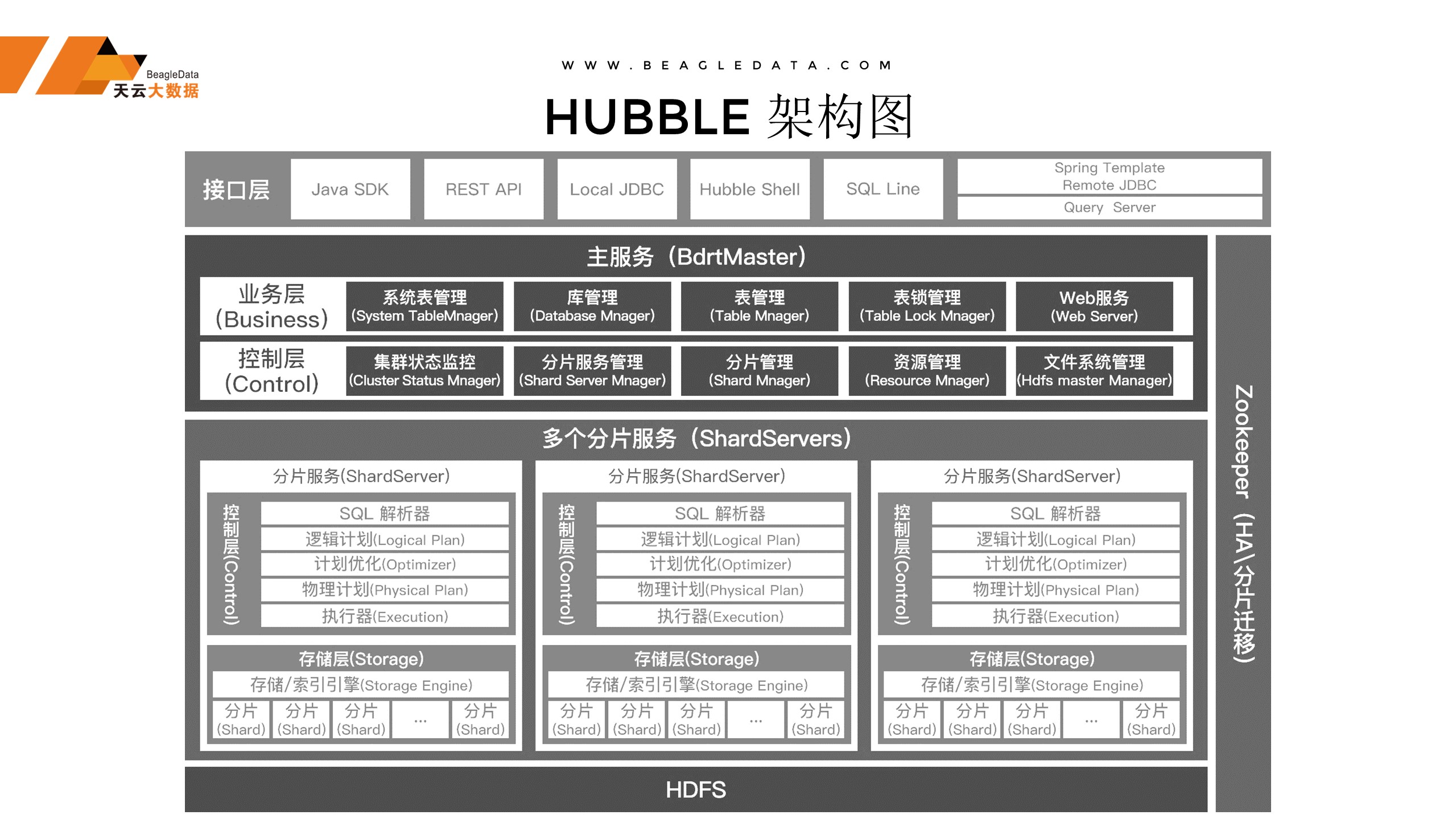
对于数据库来说稳定性是一个前提,对于稳定性的Hubble仅依赖于HDFS和Zookeeper,这是公认的在大数据界最稳定的两个组件,剩下的都是我们Hubble自有的功能,在稳定的基础之上做稳定的产品。
Hubble的定位,Hubble也是一个生态,不是一个单独的产品,Hubble首先它可以整合传统的架构,比如说数据源包括业务系统、系统的日志等等作为数据源,作为连接,包括Kafka都有现成的接口,可以直接进入到Hubble体系,Hubble体系会提供对外的应用,包括在线的应用和OLAP的场景。
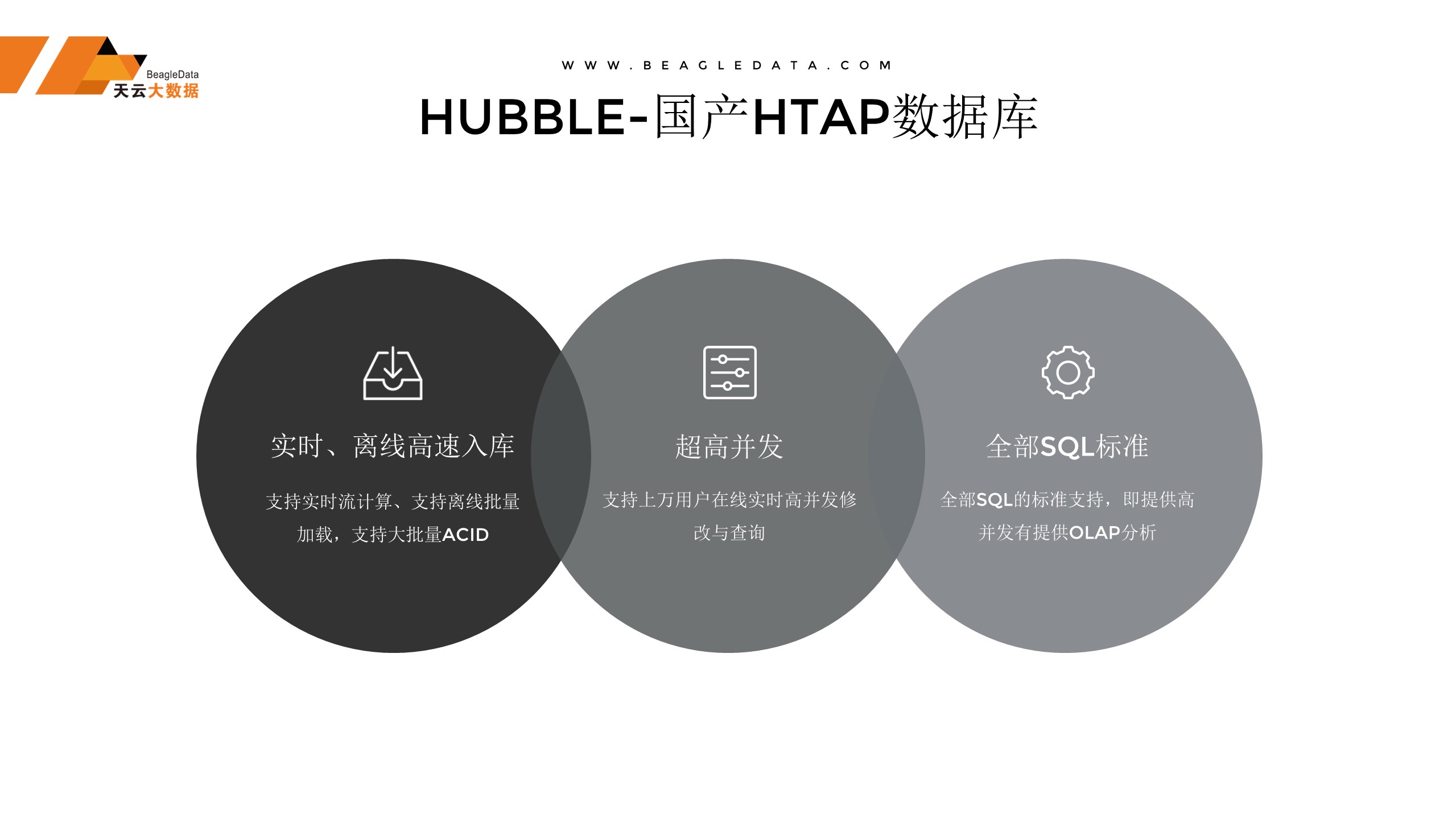
Hubble的定义是什么?就是国产的HTAP数据库,它是国内第一个实现了离线、实时的高速入库,超高并发的功能,支持全部SQL标准语法,支持上万用户的场景。
前面讲了Hubble的发展,再来看Hubble产品的介绍。首先它支持SQL语法,数据库要访问它第一个标准接口就是SQL,它是降低人员使用这个门槛的,如果说没有一个硬性标准是进不来的,其次Hubble通过了TPC-DS和TPC-H的测试,提高了它在影响力。。如果从传统的业务场景迁移到整个大数据里面来,hubble能做到几乎直接无缝迁移,直接能做到切换到大数据的应用中。

第二个就是高并发,这个很多人会说大数据比传统的要快,理解的快是Hive比传统架构快,整个大数据,在OLTP场景下没有一个比它快的。但是不光要在比传统的Mysql、Oracle快,要支持这种高并发的性能,支持海量数据。
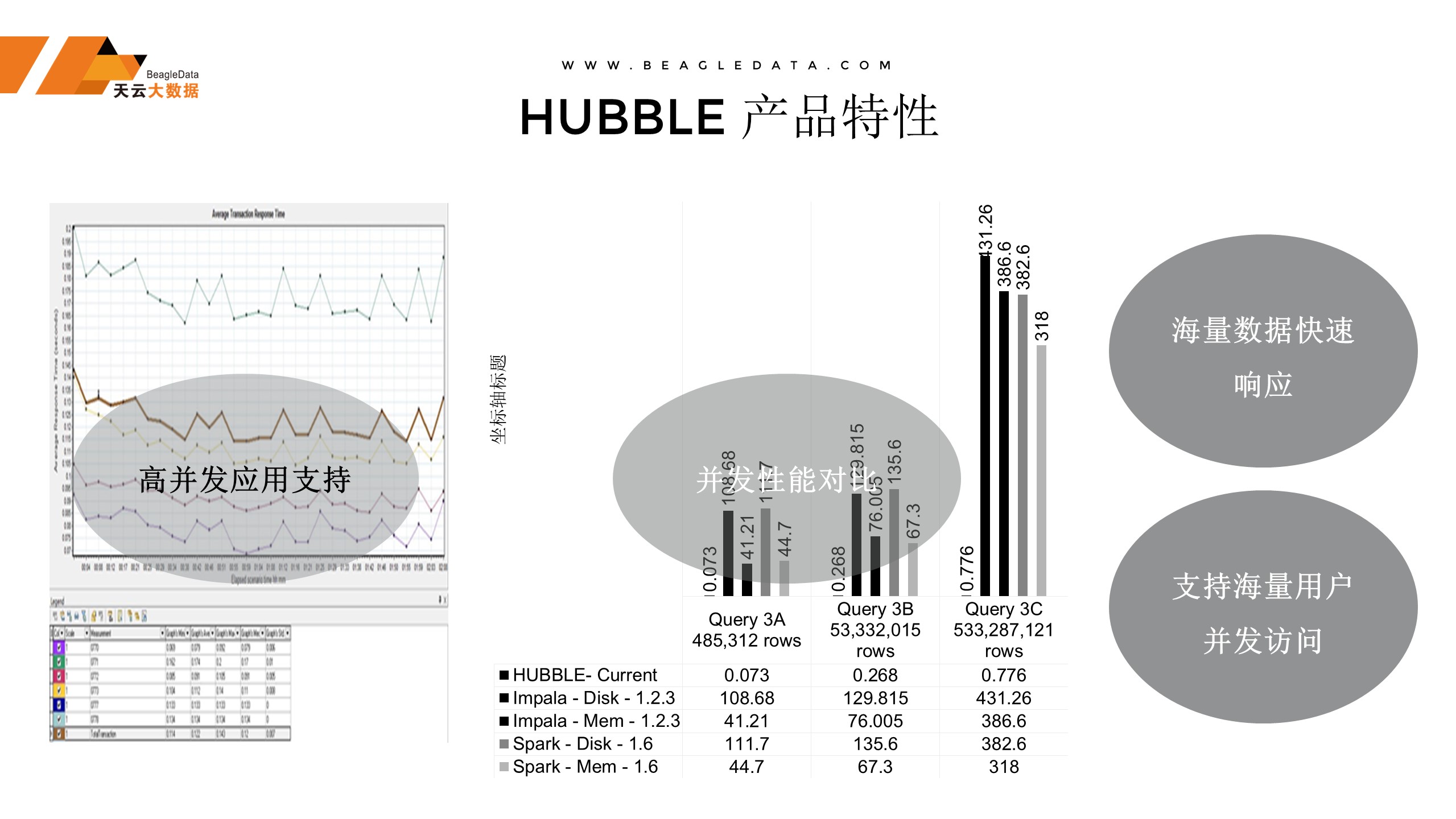
在军方的一个项目,基本上它的数据量在三千多个亿,支持海量用户的并发。
第三个特点外部表支持多种数据源,我们知道一个生态支持外部数据源,我们说HTAP是一个数据库,有一个外部表的概念,什么是外部表呢?比如你在HDFS的数据,或者本地的数据,都可以作为外部表,除了新增和更新以外,剩下表的操作都是一样的,所以我们把这些融合完之后,相当于传统架构的数据包括非结构化的数据直接做融合之后,直接做外部表的关联查询都是可以的,相当于少了一步操作就可以实际整体的迁移,或者跨库之间的融合,这是第二个特性。

最后实现了场景融合,从OLAT到OLTP的融合,可以把这个做成外部表放到我的库里面,数据融合。
场景的案例介绍,Hubble业务场景,首先是全量数据在线,就是从公司成立以来所有的数据全部可以全部在线,这个在线指的是即时,即时的数据挖掘,想要一个场景马上就响应。另外一个它是支持核心交易的。
最后一个是跨库的进行数据融合,相当于支持外部表对于外部数据跨部之间可以做关连交易和查询。
这里边列了几个业务场景,第一个核心交易应用场景,举个例子,比如我们做某大型股份制银行,它的核心交易是接近两百亿条,它的回单数据上千亿条的数据进入柜台交易,柜台输入之后立马出结果。
客户标签,我们知道用户的需求越来越多,我们怎么跟用户做业务关联,怎么实现业务标签的业务场景。
自动化运维,我们知道机器产生的数据包括应用产生的数据,量会越来越多。日志的运维也是我们场景的一部分。
最后,下一个独角兽企业会产生在哪块,可能会是做IOT的数据或者做互联网的数据。
最后说一下案例,第一个股份制银行的核心交易系统,刚才说到稳定性。从去年上线到现在,它的数据库一直运行没有发生过任何一次故障,而且没有硬件故障,比如说磁盘的坏损,包括机器硬件故障死掉之后,整个系统依然运行的非常稳定,整个系统没有出现任何的问题。
再来看,某网贷的企业信用系统,它从外部拿了很多数据,方方面面很多种,如工商的数据,包括人员的数据等等,这些数据非常之多,他有上万亿条这样的数据。
另外一个是给某家大型股份制银行搭建风险一体化中心,风险一体化相当于汇集了所有的银行内部的数据,包括整体数据的融合,做这种数据处理。
谢谢!