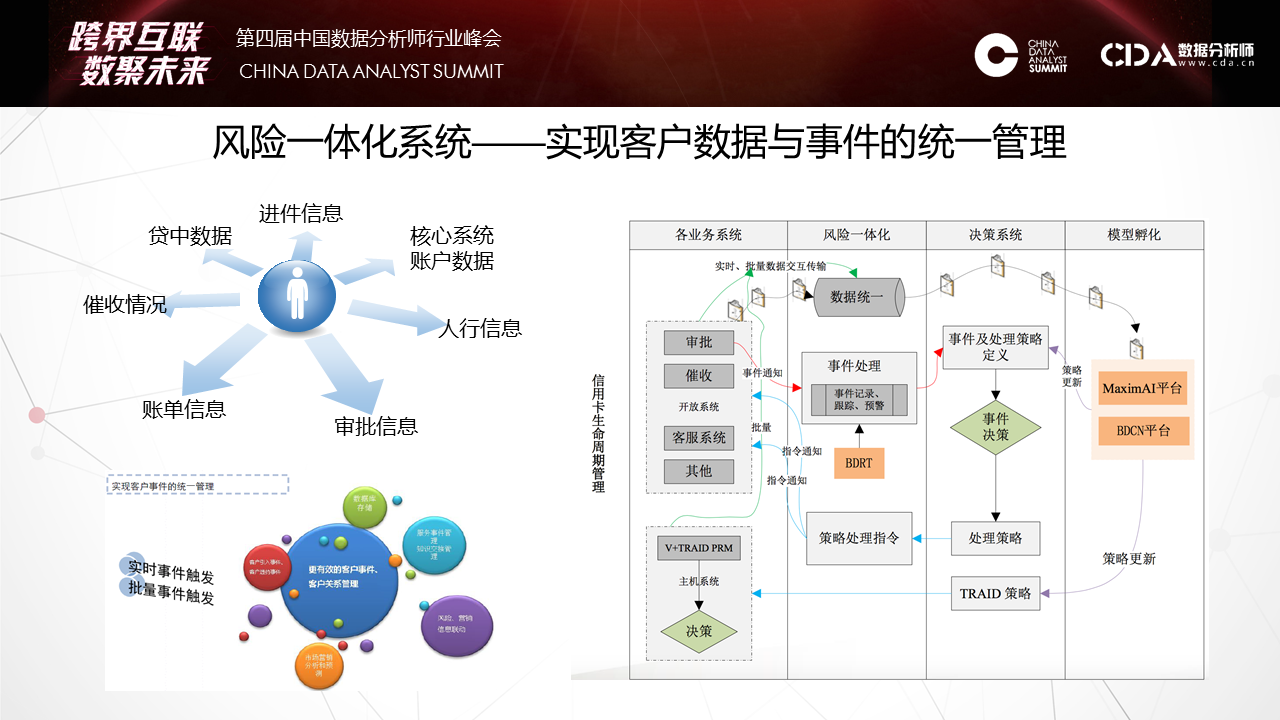
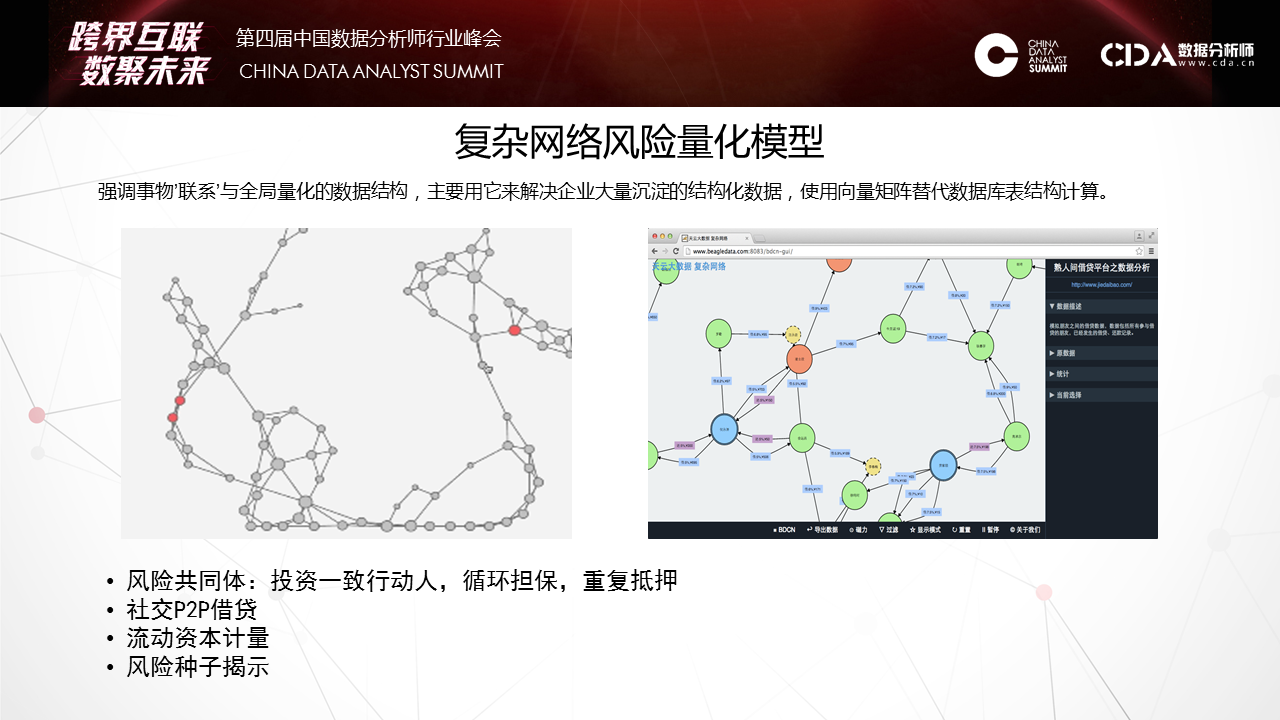
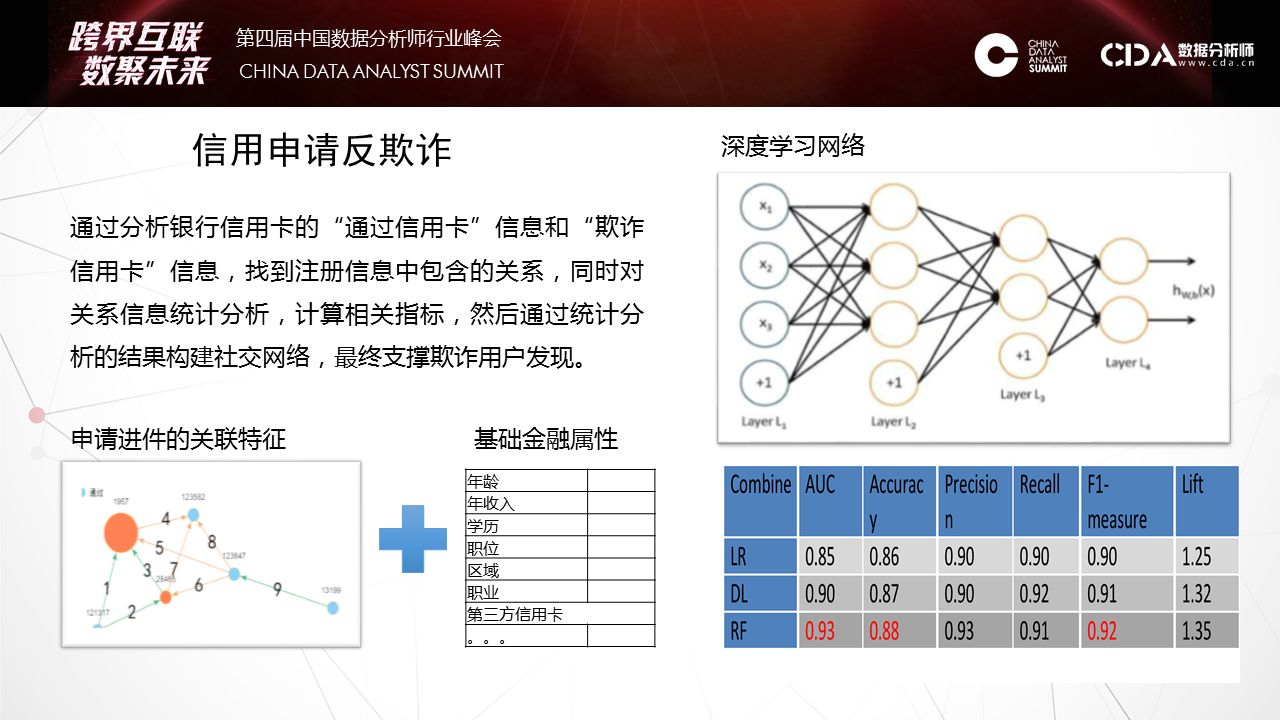
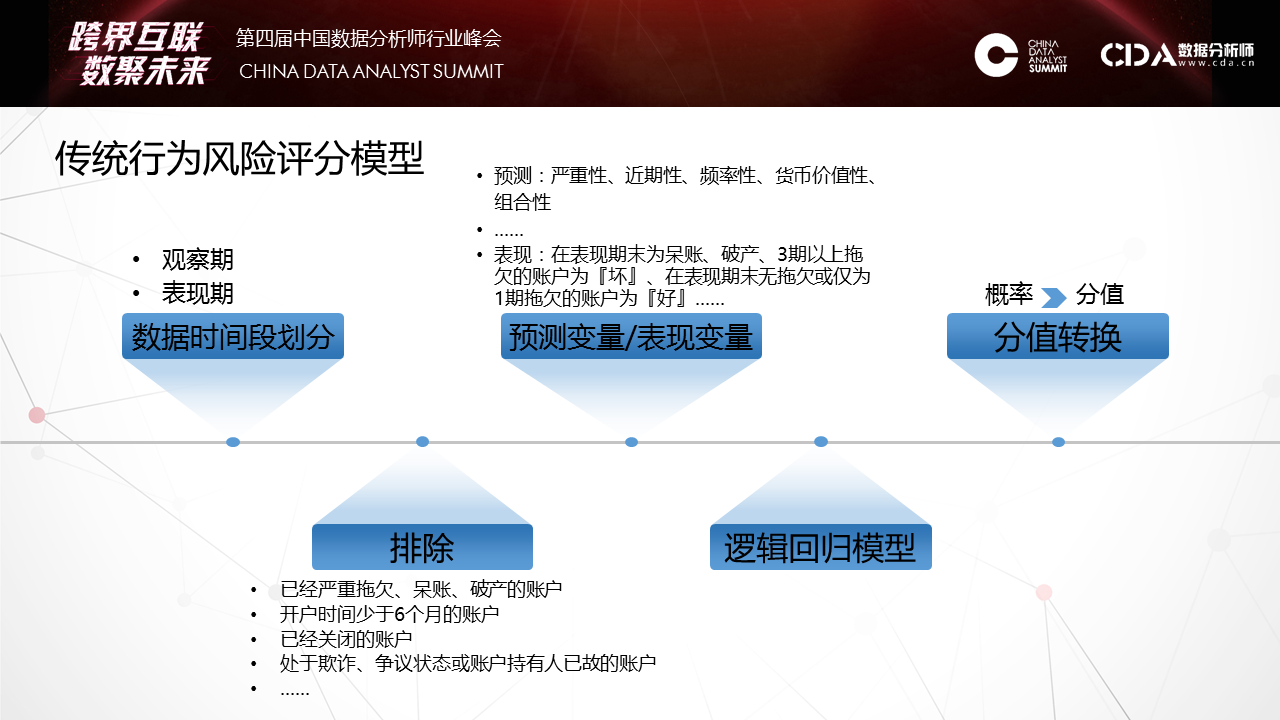
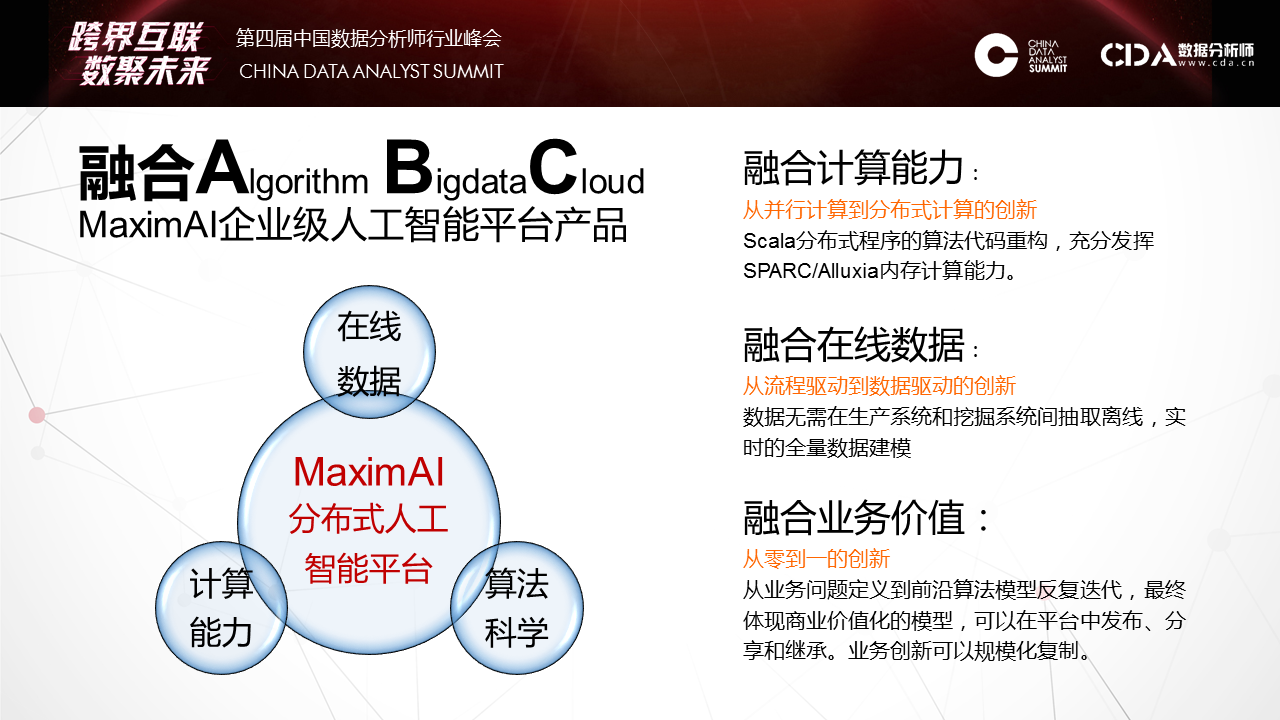
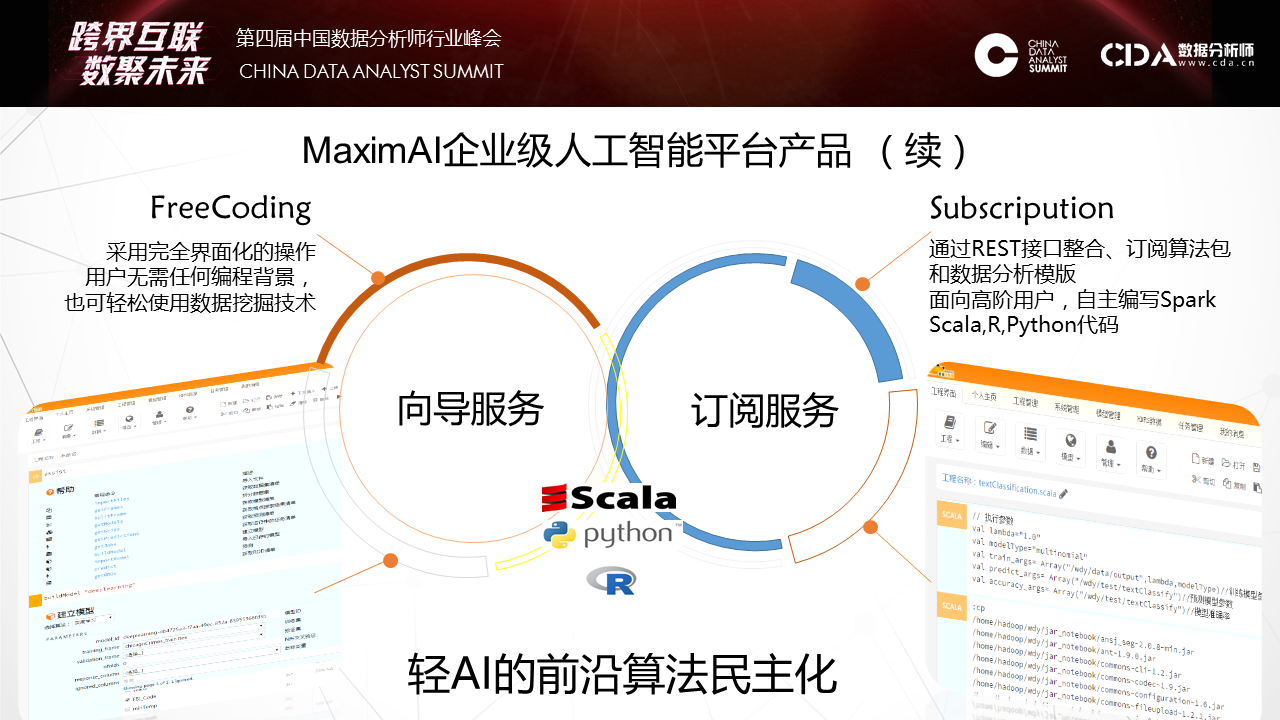
天云大数据CEO雷涛在CDAS2017数据分析师行业峰会发表演讲 7月29日,CDAS 2107中国数据分析师行业峰会「跨界互联·数聚未来」在京召开。峰会设定主论坛和11个分论坛, 涉及电商、商业BI、人工智能、大数据金融等热点话题,深层剖析前沿技术和发展趋势,本次峰会汇聚众多行业领军企业、科研院所、专家大牛等3000多名数据分析人士参会,业内人士助推大数据应用方案落地,天云大数据CEO雷涛应邀出席本次峰会并发表主题演讲。 如下为演讲全文—— 其实AI不是今天才出来的,在金融也用了很多数据挖掘,还SaaS等去做。今天的机器学习和昨天发生了很大的变化,如何规模化的将机器学习应用到银行,无论是风险,定价,反欺诈。下图的财报把亚马逊CEO推到风口浪尖,他在年度股东会上汇报的说明书里提了一句话,我们看到这句话标志AI阶段性变化。 第一个阶段,是人类将经验交给机器自动化实施。交给决策引擎就是JAVA的一套东西,自动化配置可以让机器自动化执行你从数据里挖掘出来的策略。这个经验可以拍脑袋想出来的,也可以是小数据挖掘出来的,它也比较静态,一个模型往往上线一年不会有太多的变化,是基于某个历史之前的数据挖掘出来的。今天我们会发现机器学习开始允许让我们难以精确描述规则的边界之内去完成。这是什么概念?实际上今天的机器学习因为算法和数据的规模带来一个质的提升,一个新的台阶爬上来之后,它可以完成更多我们基于答案的学习。就是人类将答案交给机器,就是当我们没有明确标准的前提下同样可以完成这个实施。在这个阶段不能回避的,第一个,我们拿什么交付给机器,这些答案是什么,这与我们传统学习发生了根本性的变化。这是我们讲的离线抽样对在线全量。像发卡是在移动端,对顾客的响应是即时即刻的。数据的鲜活和持续性给银行整个体系带来根本性的变化。第二个问题,计算能力。有时候我们常常用抽样的方法算。当我们能够有一个全局的建模方法,在线去做数据处理的时候,这样就可以用全量的数据做一些特征的表达。这是一个项目,这个典型的就是在一个银行里把一个一个孤立模型,天云怎样串接,利用数据一致性做了一个平台。这个项目事实上满足的需求,就是我们把模型与模型之间的连接通过数据动态的串起来。像它每天会跑出一百多万的卡片,第二个月还会翻。这每天的卡片数据只是每天生产流程,流程化处理,有不同节点的催收。我们可以把在线的一百多万张卡片同样跑原来的模型去算权重指标,像区域、学历等明确指标来评估。就是利用这些违约数据的答案来对审批端进行有效的调整,对它的模型进行评估。看到这张图很简单,其实它涉及到在线交易平台的系统。 后面我们会讲它在AI平台里有一个新的升维过程,怎么用到高尖的算法,像深度学习等等怎么来使用。它就是将风险在前在中在后这三个风险贯穿在一起。 第二个概念,静态个体对动态关联。这个时候我们提出一个架构,原来我们数据管理组织方式是在低维的,很多时候这种手段是不足以表达的。像我们给人民银行做的一个担保系统,在多度的情况下很难被量化,虽然可以索引到。所以我们会考虑用一种新的方法来重新表达数据。这个向量的表达数据有很多算法可以引用,但是在基础结构很少,以前没有用这个来做。所以我们也推出了新的方法,也做了一些案例。像这是九鼎的借贷保,怎么解决熟人与熟人的连接我们量化出来的风险圈。像做白条业务的时候,你没有还钱,换了一张信用卡,重新进来的时候我怎么知道是你,用这种交叉的大概十几亿节点连接起来,从全局去看个体。 这个案例不光在风险度量上,在营销上也会充分反馈。这两张图分别反映了我们两个项目的事实。这个网络就是周期太快,就是我怎么传播过程,这是C2C的传播过程,在这个过程我们要对答案激励。当资金没有到之前图是这样的,可以看到传播过程都是单点的,每一个种子节点发送以后给周边的群体后,他在朋友圈传播以后基本就结束了。这是一个网络。另外一个网络可以看到,这是一个个人的网络,这个人通过他传播以后,他像菊花一样不断的打开,因为每一个节点在重新激励,这个激励的成本其实很少的,只有一两块钱的小的红包,但是小的红包可以促发这个达人继续扩大他的营销网络。所以整个营销行为的跟踪和度量可以通过这个复杂网络实现。 第三个观点,统计评分对机器学习。传统用SaaS的时候多数的算法还是基于统计类的多,学习类的少。在学习类的今天,跟传统的学习方法上有哪些变化,我讲一下我们现在看到的一些变化。因为有数据的变化,我们表达出现了一个很大的变化,像深度学习的爆发,在几轮大赛上大家都看到深度学习很强的爆发。之前爆发的是一些特殊算法,这个特殊算法需要人强化经验抽象出去。包括在金融领域也是一样。在金融复杂的现象其实用人抽象特征的方法越来越受到挑战。这是一个例子,反欺诈,反欺诈贷中还比较好,因为贷中有大量线上行为已经暴露出来了,你有一个长项的风险暴露期。但是在申请期间是很有挑战的,因为这期间只有填申请包这么一个有限的信息,这个时候怎么表达信息,这么有限的时间内多数的方法是靠交叉验证,通过一些外部数据,或者通过一些黑名单来做,这个的覆盖率很低。所以这种环境下我们怎么把这个过程中来充分的表达出来。 我们就使用了一些新的方法,像我们会升维,我们把有限的数据用刚才关联的方法投到全球的网络,这个申请的经验表我们会把它之间的关联关系捕捉了,这种捕捉对极端犯罪非常有效。像广东有一个集团经常开着车到一个村子以招工的名义收身份证。所以发现审证件的时候,它都是真实的,真实电话,真实地址,真实的身份证号码。这种特征在一个网络环境里会暴露出来,你身边有多少片,离一片有多远,做一些升维手段后会拿到更多的社交属性。这个社交属性不是微博,而是来自身边的社交属性。这个社交属性往往在不太均衡的前提下,什么是不太均衡?像每天申请信用卡只有几百个骗子,怎么平衡,它在后台强化,可以看到最后的表达效果,像随机森林,深度学习一些不同的变化。通过这种方式我们在传统金融属性之外我们获得了一些升维的数据,然后放到深度学习网络里可以带来2-3倍识别欺诈率的提升,而且是有进展的提升。 我们可以看到一个变化,就是新的算法带来对弱特征的充分表达。这个并不是通过升维,通过引入更多的参数而获取的,而是我们通过只是使用了简单、重复的大量的数据,我们并没有说把维度扩展。这种表达给了我们一个坐标系,让很难用经验和语言描述的规则能够定量化。就像下围棋,怎么描述大局观,什么是棋风,这种可以反复迅速量化在节点上。这种思路和方法也成功的落地到金融上,尤其反欺诈,这个是最有效果的,我们在实践中看到。所以它怎么适应一些动态变化,就是靠数据持续的供应。现在在我们引入新的算法平台上有一些变化,这些变化最大的差异性实际上开始对数据和模型的角色发生变化了,传统做机器学习调参是最重要的动作,和评估某个核心的算法是核心动作,就是拿一个数据做一个假设,然后去求导它,或者用优化参数,最后得到一个上线的模型,然后结束了。它没有一个数据反馈模型。同时数据模型 本身价值,我们顶多看一下分布,然后来选择一些方法。但是我们在实践中当我们把AI平台交给客户的时候我们看到差异性,客户会对一个分类问题,会把分类算法在平台上涉及的算法都快速识别一遍,从随机森林到深度学习等都会尝试一遍,最后比较AUC的效果。所以第二轮版本干脆把用户做的也做了一个算法评估的平台,再第二期版本,直接把这些算法跑完以后,然后把评估方法给你对比出来了。这意味着什么呢?意味着我们开始重新思考数据对于模型的价值了。 事实上我们用数据不是来调优参数的,而是用数据选择算法发现,在这个选择之下我们开始考虑一个更基础的问题,就是ABC,数据科学,数据,算例,三者有效结合才是快速有效的机器算法。这三者如何有效融合?我们从2015年不断研发,最后在2016年交付了一个平台型产品,这个平台就是把算例,在此之上我们又用把主流算法包重构,算法就是让业务人员能够快速使用平台的能力。这种平台能力有提供了几种:第一,FreeCoding,这种方法能够通过配置的方式,像刚才讲的,只需要选择数据的木百在哪里,技术函数是什么等等,定义下来这些之后就可以在生产环境下在线建立一个。当然不同的算法也有很多参数,有几百个参数供你调优,如果你会就调;不会的话可以在社区讨论。所以这大大降低的应用科学的门槛。另一边就是代码,通过REST接口整合,订阅算法包和数据分析模板,面向高阶用户,自主编写Spark,Scala,R,Python代码。我们现在R放弃掉了,就像刚才老师讲的它更偏向业务,在IT上太薄弱了,因为我们是并行化平台,所以现在开始对R放弃了。现在主要聚焦在Scala和Python来推业务。 推动新技术很困难,在窄的应用环境很容易取数据,调优方法。但是现在看到越来越多的场景,现在通用的机器学习能力开始渐渐的被大家所接受了。因为大量的数据在流程里产生,大量的答案有监督的训练的前提被我们发现,在这种方式之下怎么把通用的机器学习能力快速的推到行业,推到市场。 在人工智能下一个十五年如何像安卓一样,能够将机器学习普适给行业的使用方法。比如去年四月份亚马逊的产品,还有FB的相应一系列的AI PaaS化,就是提供通用性的机器学习平台。德勤的报告给了一个很好的数据,少数斯坦福等毕业的人才98%都被Facebook等大公司囊括了,未来我想当这个能力释放给更多人群的时候就不是象牙塔里,而是能规模化,程序化和数据化,已经规模和成熟的企业,金融是一个,我们现在在Fintech刚刚起步,因为金融信息化程度比较高,未来我相信会有更多,像物联网一些数据的产生,都会到数据科学的应用里来。更多时候我期待大家从会场走出去后,放弃规则和经验,我们尝试从数据里,利用新的工具找到下一个更大的机遇爆发点。 2019年6月12日